aeneas Updates: Summer Edition
RSS • Permalink • Created 26 Aug 2015 • Written by Alberto Pettarin
During the summer I have done a lot of work on aeneas,
the Python library and set of tools to automatically align audio and text.
C Extensions
The biggest contribution consisted in porting to C code the pure Python code for extracting MFCCs and for running the DTW algorithm.
The technique, called Python C Extensions, significantly reduces the processing time of sync maps (30x-50x speedup). See here for a detailed discussion of the results.
A few comments on the C port, which debuted in v1.1.0.
First of all, the biggest portion of the gain was derived
by porting the DTW code.
In fact, the pure Python code for it (dtw.py)
relied heavily on loops while using NumPy arrays as data structure,
and the two do not mix well.
The corresponding C module (cdtw.c) contains pure C functions,
for the “at once” computation (from the MFCCs to the best path, directly)
and for each of the three steps of the computation
(MFCCs => cost matrix => accumulated cost matrix => best path),
plus the wrapper functions enabling calling these C functions from Python.
The C port of the MFCC extractor was done because
it was the other bottleneck in the end-to-end computation of a sync map.
The C module (cmfcc.c) is a nearly verbatim port of the pure Python code
(mfcc.py) deriving from the CMU Sphinx III project.
I chose this way, instead of rewriting it from scratch,
so that the results obtained by running the C code and the Python code
on the same input are consistent (up to floating point discrepancies),
albeit I would argue about some of the aspects of the original Python code.
A nice feature about the current implementation is that the code will automatically fall back to the pure Python code if, for any reasons, the C extensions could not be run (e.g., the user could not/forgot to compile them).
In fact, at first I was worried that compiling the C extensions would not work on Windows. However, I was assured (and then I tested myself) that, once you install the Microsoft Visual C++ for Python compiler, and you run the setup scripts in its special console, the C extensions are successfully compiled into the corresponding Python local modules as DLLs.
To summarize: you can enjoy running aeneas at full speed
on Linux, Mac OS X, and also Windows!
Boundary Adjustments
In v1.0.4, thanks to a generous sponsor, I added several heuristics to adjust the boundary between two consecutive text fragment.
The idea is simple: depending on your application (Audio-eBooks, closed captions, etc.), you might want to slightly change the time instant where the current fragment ends and the next one starts.
For example, if you are preparing an Audio-eBook,
you might want to anticipate the splitting point
by, say, 0.200 s (200 ms), so that
the audio is played with a small delay when the user
performs a tap-to-play touch.
For closed captioning applications, you might want to adjust the timings so that the rate (characters/s) of the subtitles is kept below a given maximum rate. For example, the TED OTP project recommends a maximum rate of 21 characters/s.
The v1.0.4 implementation (then expanded in v1.1.0)
adds several adjustment algorithms (adjustboundaryalgorithm.py).
Most of them are based on the concept of non-speech interval
between two consecutive text fragments.
A non-speech interval (NSI) is a portion of the audio file
where there is no recognized speech activity (silence, background noise, etc.).
The non-speech intervals are detected by aeneas
using an energy-based voice activity detector (VAD) algorithm (vad.py).
In the next figure, the NSIs are indicated by red segments.
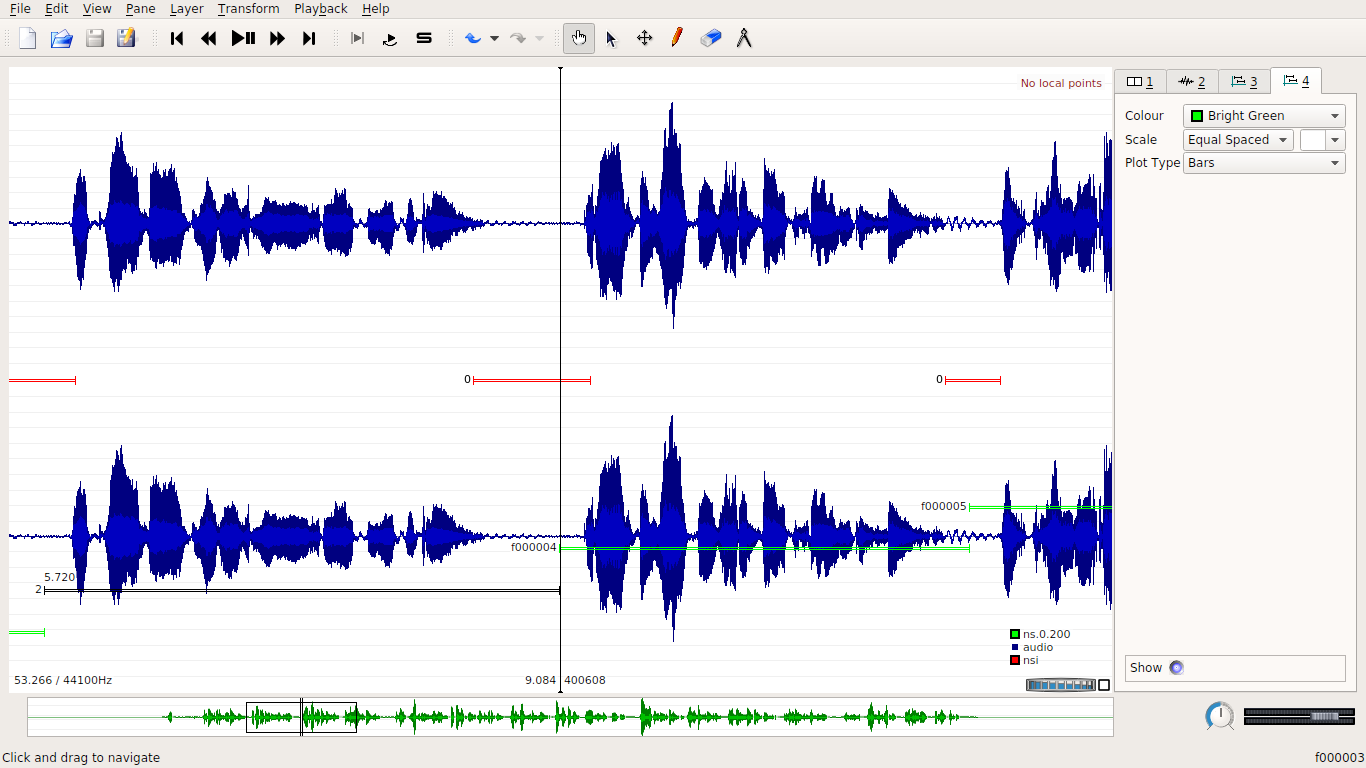
Each implemented heuristic will examine the “raw” boundary points (that is, as determined by the MFCC+DTW aligner), one at a time, and, for each, it will determine if there is an NSI spanning it.
Then, it might or might not modify it, depending on the heuristic
(and the value of x) required by the user:
AUTO: do not modify the current boundary;AFTERCURRENT: set the boundary atxseconds after the beginning of the NSI;BEFORENEXT: set the boundary atxseconds before the end of the NSI;PERCENT: set the boundary atxpercent of the length of the NSI;OFFSET: offset the current boundary byxseconds (positive or negative);RATE: modify the boundary trying to respect thexcharacters/s max rate;RATEAGGRESSIVE: similar toRATE, but more aggressive;
In the above picture, the BEFORENEXT method was used,
moving the boundary 200ms ahead.
The NSIs are the red segments, the text fragments are the green segments.
Note that OFFSET and RATEAGGRESSIVE do not take NSIs into account.
All methods have checks to avoid creating pathological sync maps,
for example avoiding moving boundaries outside NSIs
or shrinking/expanding fragments too much.
Please also note that these are heuristics,
so there is no guarantee that they will work 100% on any arbitrary audio file.
Do some experiments to find out whether they work for your materials.
You can tweak their behavior by changing some global constants
in the corresponding source file.
Finally, running one of the adjustment algorithms is completely optional:
if you are happy with the raw boundaries, just do not specify
any adjustment algorithm in the config string/file
when running aeneas.tools.execute_task or aeneas.tools.execute_job.
Google Group
I also started a Google Group for aeneas, mainly
to broadcast announcements, offer support,
and gather feedback from the users.
The mailing list archive can be read online here.
I strongly encouraging aeneas users to join it,
by requesting an invitation via email (aeneas@readbeyond.it)
or reaching to me directly.
Running on Windows
Richard Margetts from SIL International
kindly wrote detailed directions
to install aeneas natively on Windows,
which are now linked in the README on GitHub.
Other users confirmed that they succeeded in installing aeneas
on Windows, and later I did it myself on a borrowed laptop running Windows Vista.
The Python C Extensions works too; v1.1.1 added a BAT script (again provided by Richard Margetts) to set them up automatically, in a fashion similar to the existing setup Bash script for Linux/OS X.