Solving (Generalized) Ruzzle Boards With elzzur
RSS • Permalink • Created 29 May 2016 • Written by Alberto Pettarin
Ruzzle is a word board game app which went viral a few years ago.
A 4-by-4 board of letters is shown to the player:
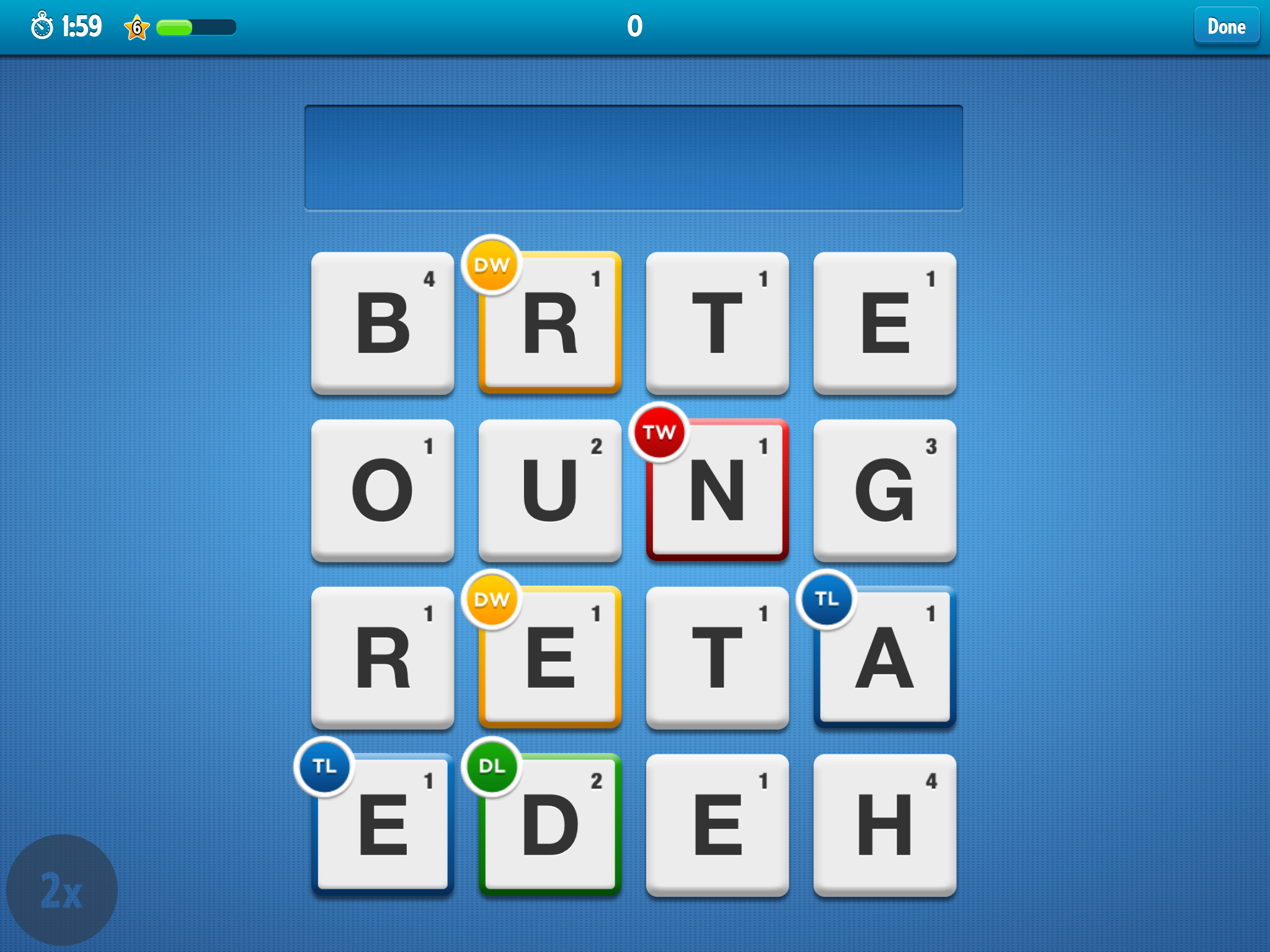
and she has two minutes to find as many valid words in the board as she can.
A word can be formed by connecting at least two adjacent letters (including above/below, left/right, or diagonally), and it is valid if it is present in the app dictionary for the language chosen by the user. For example, “THE” in the above board:
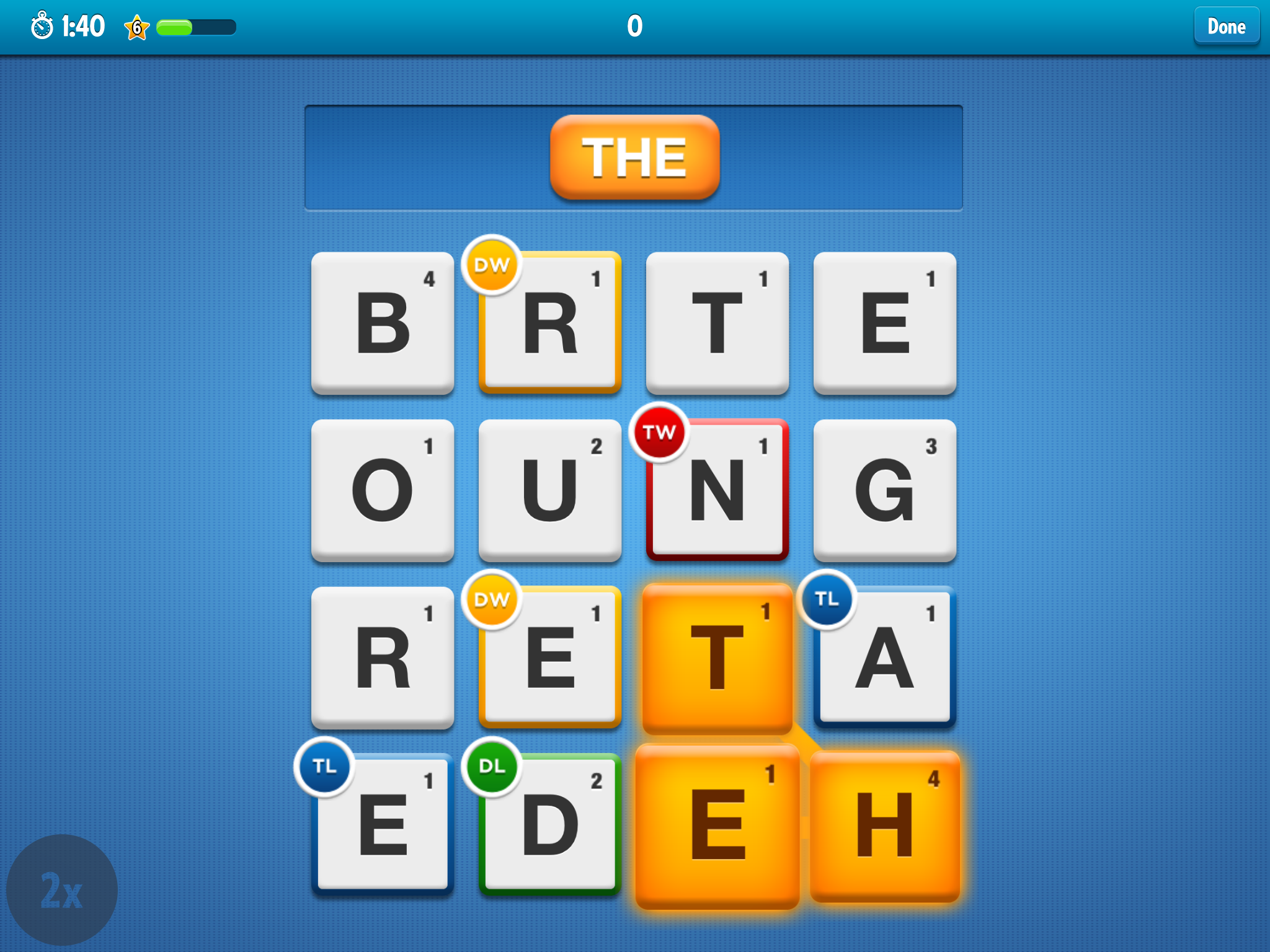
The total score is the sum of the scores of the words found, which in turn is the sum of the points of each letter in the word, potentially multiplied by two or three if the path forming the word includes letters with the DL/TL/DW/TW modifiers. Also, 5-letters words or longer are awarded bonus length points.
Note that the score of each letter differs from language to language, since it basically depends on the frequency of the letter in each language, as in other word board games like Scrabble. For example, a “C” is worth 4 points in English, but only 2 points in Italian, etc.
(For details on the Ruzzle rules, see the Scoring Rules Section.)
Kids Challenging The Wrong Uncle
Two of my nephews are quite addicted to this game app, which allows remote players to compete on the same board, the winner being the player achieving a score higher than the opponent.
While I like playing the game myself from time to time, especially with or against my nephews, I also see some serious problems in it. The worst one is that, given a board, it is extremely easy to achieve an astronomical score by cheating. In fact, I mentioned to my nephews (they are 7 and 10 years old) that it is rather straightforward to write a program that, in few seconds, enumerates all the words contained in the very board displayed by the app. They were skeptical, so I had to show them some magic!
Enters elzzur
I coded elzzur, a Python package
that contains an executable script which in fact solves any given Ruzzle board.
(Yes, “elzzur” is “ruzzle” backwards…)
Unlike other solvers out there, elzzur solves generalized boards,
that is, N-by-M boards (N, M >= 1), not just 4-by-4 boards.
Moreover, it does not just find the words, but it also computes their exact score, thanks to built-in letter scores for a handful of languages, taken from the actual Ruzzle app. The user can sort the results by score, word length, or begin/end cell. In particular, sorting by (decreasing) score ensures the highest degree of “cheatiness”…
Finally, elzzur has built-in dictionaries
derived from the GNU aspell project.
Although the built-in dictionaries are not the Ruzzle official ones,
they are sufficiently extensive to prove my point.
(I guess you can obtain the official Ruzzle dictionaries
by decompiling the app, and maybe they are already out there,
in the dark corners of the Internet…)
Alternatively, the user can supply her own dictionary.
Using elzzur
OK, enough talk, let’s play!
First, install it:
$ pip install elzzur
Installing via pip will make the elzzur script available in your shell:
$ elzzur --help
usage: __main__.py [-h] [-l [LANGUAGE]] [-d [DICTIONARY]] [-b [BOARD]]
[-o [OUTPUT]] [-r [ROWS]] [-c [COLS]] [-s [SORT]] [-R] [-q]
command
elzzur solves a Ruzzle board
positional arguments:
command [cat|compile|demo|generate|languages|solve]
optional arguments:
-h, --help show this help message and exit
-l [LANGUAGE], --language [LANGUAGE]
Language code (e.g., 'en')
-d [DICTIONARY], --dictionary [DICTIONARY]
Path to the dictionary file
-b [BOARD], --board [BOARD]
Path to the board file
-o [OUTPUT], --output [OUTPUT]
Path to the output file
-r [ROWS], --rows [ROWS]
The number of rows of the board to generate
-c [COLS], --cols [COLS]
The number of columns of the board to generate
-s [SORT], --sort [SORT]
Sort words by [score|length|start|end]
-R, --reverse Reverse the list of words
-q, --quiet Do not output board and statistics
(If you clone the GitHub repo or you use Windows, replace elzzur with python -m elzzur.)
For the impatient, elzzur comes with a “demo” mode,
which shows a built-in 4-by-4 board,
generated by the official Ruzzle app,
and solves it.
For example, for English (-l en), it prints:
$ elzzur demo -l en
Ttl R S Ndl
Odw Htw E I
Cdw I N V
Etl A D E
COHESIVE 224 (2,0) (1,0) (1,1) (1,2) (0,2) (1,3) (2,3) (3,3)
HEROIC 154 (1,1) (1,2) (0,1) (1,0) (2,1) (2,0)
CHORES 154 (2,0) (1,1) (1,0) (0,1) (1,2) (0,2)
COHEN 149 (2,0) (1,0) (1,1) (1,2) (0,3)
ECHO 144 (3,0) (2,0) (1,1) (1,0)
ROCHE 137 (0,1) (1,0) (2,0) (1,1) (1,2)
OCHRE 137 (1,0) (2,0) (1,1) (0,1) (1,2)
OCHER 137 (1,0) (2,0) (1,1) (1,2) (0,1)
NACHO 137 (2,2) (3,1) (2,0) (1,1) (1,0)
CHORE 137 (2,0) (1,1) (1,0) (0,1) (1,2)
ACHIEVED 128 (3,1) (2,0) (1,1) (2,1) (1,2) (2,3) (3,3) (3,2)
ACHIEVE 111 (3,1) (2,0) (1,1) (2,1) (1,2) (2,3) (3,3)
OCH 108 (1,0) (2,0) (1,1)
...
IS 2 (1,3) (0,2)
IA 2 (2,1) (3,1)
ES 2 (1,2) (0,2)
ER 2 (1,2) (0,1)
AN 2 (3,1) (2,2)
AI 2 (3,1) (2,1)
Number of words: 281
Length of the longest word: 8
Maximum total score: 7376
As you can see from the output above,
you also get the (0,0)-based coordinates
of the cells of the board that generate each word.
Clearly, for Italian (-l it)
you will get a different board
and a different list of words:
$ elzzur demo -l it
Ztl T Edw Edl
I N R I
Itw Adw M U
A Ctl A Z
MACINARE 236 (2,2) (3,2) (3,1) (2,0) (1,1) (2,1) (1,2) (0,2)
CINERAMA 236 (3,1) (2,0) (1,1) (0,2) (1,2) (2,1) (2,2) (3,2)
CINZIA 226 (3,1) (2,0) (1,1) (0,0) (1,0) (2,1)
TENACIA 195 (0,1) (0,2) (1,1) (2,1) (3,1) (2,0) (3,0)
IRENICA 195 (1,3) (1,2) (0,2) (1,1) (2,0) (3,1) (2,1)
MACINE 190 (2,2) (2,1) (3,1) (2,0) (1,1) (0,2)
...
MIR 6 (2,2) (1,3) (1,2)
ITRI 6 (1,0) (0,1) (1,2) (1,3)
TI 3 (0,1) (1,0)
Number of words: 111
Length of the longest word: 9
Maximum total score: 5566
Run with the languages command to list the supported languages,
that is, languages for which the letter score and frequency,
a demo board, and a dictionary,
are built in elzzur:
$ elzzur languages
Supported languages: de, en, es, fr, it, nl, pt
At this point, you might want to solve your own board.
To do so, create a plain text file, say /tmp/my.board,
containing something like the following four lines
(details on the format are here):
B Rdw T E
O U Ntw G
R Edw T Atl
Etl Ddl E H
and then run:
$ elzzur solve -l en -b /tmp/my.board
B Rdw T E
O U Ntw G
R Edw T Atl
Etl Ddl E H
BURNED 166 (0,0) (1,1) (0,1) (1,2) (2,1) (3,1)
TURNED 130 (0,2) (1,1) (0,1) (1,2) (2,1) (3,1)
BURNER 130 (0,0) (1,1) (0,1) (1,2) (2,1) (2,0)
BRUNET 130 (0,0) (0,1) (1,1) (1,2) (2,1) (2,2)
DENATURE 116 (3,1) (2,1) (1,2) (2,3) (2,2) (1,1) (2,0) (3,0)
ORNATE 106 (1,0) (0,1) (1,2) (2,3) (2,2) (2,1)
URETHANE 104 (1,1) (2,0) (2,1) (2,2) (3,3) (2,3) (1,2) (0,3)
BORNE 101 (0,0) (1,0) (0,1) (1,2) (2,1)
...
TUT 4 (0,2) (1,1) (2,2)
OUT 4 (1,0) (1,1) (0,2)
UT 3 (1,1) (0,2)
TU 3 (0,2) (1,1)
Number of words: 238
Length of the longest word: 8
Maximum total score: 6762
In all the above examples the dictionary used is the built-in one.
However, you can pass your own dictionary
(details are here)
to the solver, using the -d switch:
$ cat /tmp/my.dictionary
BAR
BAZ
BURNED
FOO
OUT
$ elzzur solve -l en -b /tmp/my.board -d /tmp/my.dictionary
B Rdw T E
O U Ntw G
R Edw T Atl
Etl Ddl E H
BURNED 166 (0,0) (1,1) (0,1) (1,2) (2,1) (3,1)
OUT 4 (1,0) (1,1) (0,2)
Number of words: 2
Length of the longest word: 6
Maximum total score: 170
If you plan to create a full dictionary with thousands of words, you might want to compile it to MARISA format, so that loading it into memory will be faster than loading it from a plain-text file:
$ elzzur compile -d /tmp/my.dictionary -o /tmp/my.dictionary.marisa
File '/tmp/my.dictionary.marisa' saved
$ elzzur solve -l en -b /tmp/my.board -d /tmp/my.dictionary.marisa
...
Finally, if you want to generate random boards,
elzzur can do it for you, sampling letters
according to the letter frequency of the selected language:
# generate a 4x4 English board
$ elzzur generate -l en
Utl Ldw D L
Utw Htl Stl Itl
T A Ddw T
Utl E Hdw Mdw
# generate another 4x4 English board
$ elzzur generate -l en
T B F T
F T P Sdl
Atw F A G
T Stw A T
# generate a 6x6 English board
$ elzzur generate -l en -r 6 -c 6
R A I A O B
W A T W A F
O D O Wdw M S
H Ttl I T T Tdw
Itl T Htw A F Ctw
W T Tdl E J A
# generate a 6x10 English board, piping it to file
$ elzzur generate -l en -r 6 -c 10 > /tmp/my_6x10.board
$ cat /tmp/my_6x10.board
Otl B Fdl H B Tdl E Mdw Tdw Tdw
A Mdl D Fdw Hdl P P Stw T Itl
D S H W M N Wtl Idw T O
Ctl Adl Wtl S Idw Wdl Hdl Y Gtl S
T M Pdw Idl W A Wdw U Wdw Edl
Adl Rdw S H Atl T A T T Kdw
And, as promised, the solver can take it!
$ elzzur solve -l en -b /tmp/my_6x10.board
Otl B Fdl H B Tdl E Mdw Tdw Tdw
A Mdl D Fdw Hdl P P Stw T Itl
D S H W M N Wtl Idw T O
Ctl Adl Wtl S Idw Wdl Hdl Y Gtl S
T M Pdw Idl W A Wdw U Wdw Edl
Adl Rdw S H Atl T A T T Kdw
WHIST 365 (4,6) (3,6) (2,7) (1,7) (0,8)
HIPPEST 255 (3,6) (2,7) (1,6) (1,5) (0,6) (1,7) (0,8)
EGOTISM 231 (4,9) (3,8) (2,9) (1,8) (2,7) (1,7) (0,7)
WHIPS 221 (4,6) (3,6) (2,7) (1,6) (1,7)
...
TO 2 (1,8) (2,9)
SO 2 (3,9) (2,9)
OT 2 (2,9) (1,8)
OS 2 (2,9) (3,9)
Number of words: 514
Length of the longest word: 8
Maximum total score: 13695
Who Is MARISA? Or, A Few Words On The Solver
I really enjoyed coding elzzur, because it gave me an excuse to use
one of my favourite data structures: a trie, also known as prefix tree.
In particular, I used a MARISA trie, a very efficient C++ implementation
of a recursive, bit-indexed trie,
wrapped by the Python binding marisa-trie.
Given the dictionary of valid words, “solving” a Ruzzle board means returning the list of words on the board maximing the total score.
Since the total score is the sum of the scores of the words found, this optmization problem can be solved by:
- finding all the possible valid “snakes”, that is, paths of adjacent cells forming words present in the dictionary; and
- computing the score of each snake: if two or more snakes form the same word, only one yielding the highest score must be kept, since the Ruzzle rules say that the player cannot form the same word twice.
While the second step is trivial, the first one requires some thinking.
Attempt 1: Brute Force Search Of The Board
A naive attempt is the following: enumerating all the possible snakes, for example by performing a depth-first search (DFS) or a breadth-first search (BFS) of the board, checking if the word corresponding to the each snake is contained in the dictionary. To check efficiently, the latter can be stored as an hash table in memory.
This naive approach takes a lot of time, since there are about 12 million possible snakes in a 4-by-4 board. To meet the 2-minutes constraint of the original app, each snake should be generated and checked against the dictionary in about 10 microseconds, which is not quite feasible in Python (or even C) with a 100k word dictionary. Even worse, the number of snakes increases exponentially with the size of the board: solving a (say) 10x10 board will take ages on a regular PC.
Attempt 2: A Smarter Search
A better approach consists in reversing the role of the dictionary and the board, since natural languages have less than a million words (including inflected forms), so looping through the dictionary, checking if the current word can be formed on the given board is faster. A further speedup stems from the observation that one can filter the dictionary, removing words that cannot be formed with the letters present on the board, for example all those containing “Z” if “Z” is not on the board, or all those containing three “E”s if the board contains only two “E”s, etc.
However, even with this optimization, the (Python) code I wrote to benchmark it took a few minutes to solve a 4-by-4 board, and not making the 2-minutes cut of the official Ruzzle app!
Attempt 3: Trie-based Dictionary Search
The two attempts described above highlight a key characteristic of the problem.
Suppose you are examining a “current” snake. First, you check if it is a valid word: if so, you store it in the list of valid snakes. Second, you need to extend it, that is, you need to generate new “candidate” snakes, to be examined later, by appending letters adjacent to the current end letter. But of course you can avoid exploring these extensions if you know that no word in the dictionary has a prefix equal to the current snake. An example will help understanding the process:

Suppose you have the snake “BURN”. Since it is a valid English word, you will store it. Now, you examine the letters adjacent to the “N”: except for the “R” and “U” letters, which are already part of the current snake and hence they cannot be used again, you will add “BURNT” (top), “BURNE” (top-right), “BURNG”, “BURNA”, “BURNT” (bottom), and “BURNE” (bottom-left) to the queue of snakes to be examined. In fact, at a later iteration:
- both “BURNT” will be added to the the list of valid snakes, since “BURNT” is in the dictionary, and it will not be explored further, as no other word starts with prefix “BURNT”;
- “BURNE” is not a valid word, but the dictionary has words like “BURNED”, “BURNER” or “BURNETT” which start with that prefix, hence it will be explored further: “BURNED” is indeed on the board and it will be found in a later iteration;
- “BURNA” is not a valid word, but the dictionary contains “BURNABLE”, so it will not be added but it will be explored: since none of “BURNAG”, “BURNAH”, “BURNAE”, or “BURNAT” is a prefix of a dictionary word, the exploration will be pruned in the subsequent iteration;
- “BURNG” is neither a valid word nor a prefix of a valid word, so it will not be added and it will not be explored.
This observation immediately suggests to store the dictionary in a data structure that answers the following two questions efficiently:
- deos the data structure contain word
w? - does the data structure contain words starting with prefix
p?
Of course, such a data structure is a trie, aka prefix-tree aka radix-tree.
A trie is a tree with an empty root, while other nodes corresponds to one or more letters. Nodes that are children of the same node represent words that share the same prefix, which is precisely the concatenation of letters in the path from the root to the common parent node, but that then differ in the next letter. The following illustration makes the concept intuitive:
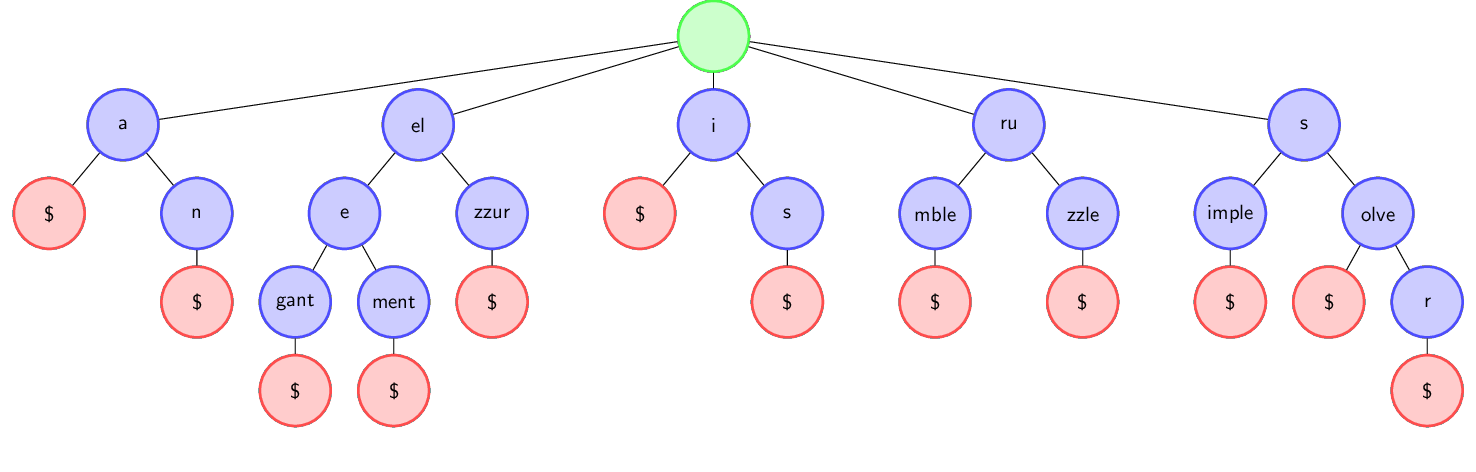
The words stored in the trie depicted above are: a, an, elegant, element, elzzur, i, is, rumble, ruzzle, simple, solve, solver.
Since a dictionary might contain words that are prefixes of other words,
like “solve”/”solver” in the example, a virtual character, $ in the example,
is added at the end of a word, to indicate that a prefix (“solve”) is also a full word (“solve$”).
(Actual implementations use a bit field for each node, instead of adding these virtual leaves,
but I find easier to understand the $-convention shown above.)
To determine whether a word is stored in the trie, a visit of the trie starts from the root, until a leaf node is reached (which means the word is present) or a failure occurs. When reaching an internal node, its children are scanned to see if one contains a prefix of the word: if not, the search fail; if yes, the search continues from the child. For this reason, siblings are usually kept sorted, to allow binary search. In the above trie, seaching for “elementary”, “solver” and “solving” will visit the following nodes:
elementary: ROOT => el => (el)e => (ele)ment => NOT FOUND
solver: ROOT => s => (s)olve => (solve)r => (solver)$ => FOUND
solving: ROOT => s => NOT FOUND
Answering both the above questions (“has a given word?” and “has words with given prefix?”) requires to traverse at most h nodes, where h is the height of the tree, each costing a binary search over the prefixes stored in its children. (For alphabets of limited cardinality, one can use an hash table or an array, trading space to achieve access in constant time.) Due to the statistical properties of natural languages, not all sequences of letters appear with the same frequency, and hence most of the times the search of the trie is terminated early, which in turn means that the exploration of the board is heavily pruned.
In elzzur, the solver is thus implemented as in the following Python-like pseudo-code:
func find_valid_snakes(board, dictionary):
valid_snakes = []
for row in board.rows:
for col in board.cols:
q = [board.letter(row, col)]
while len(q) > 0:
current_snake = q.pop()
if dictionary.has_word(current_snake):
valid_snakes.append(current_snake)
if dictionary.had_words_with_prefix(current_snake):
# generate new candidate snakes by appending letters
# adjacent to current snake end letter
for (cand_row, cand_col) in board.adjacent_letters(current_snake.end):
# the extended snake cannot intersect itself
if not (cand_row, cand_col) in current_snake:
q.append(current_snake + board.letter(cand_row, cand_col))
return valid_snakes
Here q is a queue simulating a BFS of the board grid,
but the type of search does not really matter,
a DFS would have worked equally well.
What really matters is the fact that dictionary
supports fast has_word() and has_words_with_prefix() operations.
The actual Python code for the above function is here.
Once all the valid snakes are found, it is just a matter of keeping the highest scoring one (if two or more yield the same word), and sorting them according to the method requested by the user: score, word length, or begin or end cell of the snake.
As promised, the code using a MARISA trie to store the dictionary is really fast, taking only a few hundred milliseconds to solve a 4-by-4 board:
$ time elzzur solve -l en -b /tmp/my_4x4.board
...
real 0m0.456s
user 0m0.420s
sys 0m0.032s
$ time elzzur solve -l en -b /tmp/my_10x10.board
...
real 0m2.393s
user 0m1.868s
sys 0m0.040s
$ time elzzur solve -l en -b /tmp/my_20x20.board
...
real 0m8.384s
user 0m5.416s
sys 0m0.096s
$ time elzzur solve -l en -b /tmp/my_50x50.board
...
real 0m40.112s
user 0m37.796s
sys 0m0.332s
$ time elzzur solve -l en -b /tmp/my_100x100.board
...
real 2m44.642s
user 2m35.208s
sys 0m1.328s
The sharp-eyed reader will notice that the run time is roughly linear in the number of cells of the board…
More Fun (aka Open Problems And Future Work)
On the GitHub README I listed a few extensions that are worth exploring.
If you fancy combinatorics, obtaining a closed formula for the number of possible snakes in a N-by-M grid seems to be an open problem, the main difficulty being the “geometric” constraints induced by the “non-self-intersecting rule”.
Did you enjoy reading this post? Let me know by email or via Twitter (@acutebit).
(I am considering writing a series of posts similar to this one, about non-trivial algorithms and data structures, and their applications to practical and/or fun problems, so feedback is very appreciated.)
Enjoy playing with elzzur!