Inside aeneas Part 1: Motivation And Design Principles
RSS • Permalink • Created 03 Aug 2016 • Written by Alberto Pettarin
In June 2016 I started writing a post about the first “FLOSS birthday” of aeneas, as its source code was pushed to GitHub on May 2015, but eventually I gave up writing that post up.
Over time it grew larger and larger, accumulating etherogeneous themes and ideas, to the extent I have never been satisfied to publish it on this blog, mostly for its length and lack of coherence. Moreover, recently I published a new version of the package, aeneas v1.5.1, shipping changes that required me to modify important parts of what I previously wrote, most notably installers and static builds for Windows and Mac OS X.
Since I believe that what I am going to say is important, I decided that the best strategy to eventually have it written down (and hopefully read and spread around) consists in splitting it into several smaller Inside aeneas blog posts.
In this first post I discuss the problem aeneas tries to solve, and the design principles adopted to address it.
Prelude: A Brief Definition Of Force Alignment
It might be useful to remind that aeneas is mainly a forced aligner (FA), that is, a software that takes an audio file and a text file divided into fragments as its input, and it outputs a synchronization map, that is, it automatically associates to each text fragment the time interval (in the audio file) when that text fragment is spoken. The following waveform illustrates the concept:
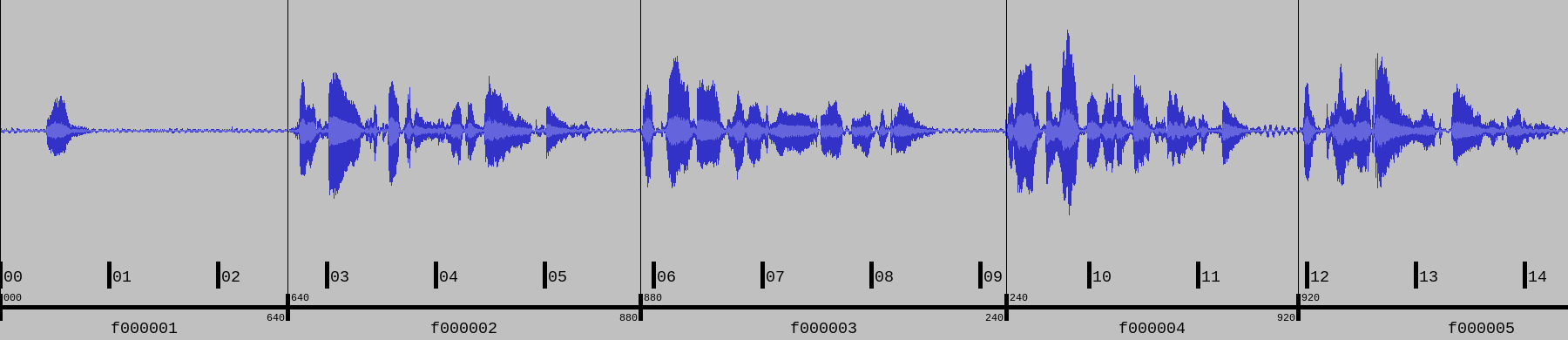
1 => [00:00:00.000, 00:00:02.640]
From fairest creatures we desire increase, => [00:00:02.640, 00:00:05.880]
That thereby beauty's rose might never die, => [00:00:05.880, 00:00:09.240]
But as the riper should by time decease, => [00:00:09.240, 00:00:11.920]
His tender heir might bear his memory: => [00:00:11.920, 00:00:15.280]
...
Typical applications of FA include Audio-eBooks where audio and text are synchronized, or closed captioning for videos.
FA systems are handy because they output the synchronization map automatically, without requiring any human intervention. In fact, manually aligning audio and text is a painfully tiring task, prone to fatigue errors, and it requires trained operators who understand the language being spoken. FA software can do the job effortlessly, while maintaining a good quality of the alignment output, often indistinguishable from a manual alignment.
Finding A Robust, Multi-language FLOSS Forced Aligner
Back in 2012, when I started creating what eventually I ended up calling EPUB 3 Audio-eBooks, I began researching FA packages.
While there were (and still are) commercial, closed-source forced aligners out there, they were (and still are) all extremely expensive, some requiring from 1k USD/year license to 10k USD one-time license, which was totally unaffordable for me at that time. (To give a rough term of comparison, here in Italy an hour of manual alignment costs between 30 to 120 Euro, depending on the type of contents, legal or technical transcripts being the most expensive. The cheapest service I have ever found online requested about 20 USD per hour of processed audio.)
On the other hand, there were a few open source FAs from research projects in academia, providing forced alignment as a by-product of their “main business”, that is, automatic speech recognition (ASR). In the last 3 years their number grew a bit, thanks to other research groups or individuals publishing their code online, but they still have the same major drawbacks:
- they lack pre-trained models for languages other than English (and training your own is expensive and/or technically difficult);
- they are complex to install and run;
- the end user must have at least some speech processing knowledge to use them;
- in many cases, their licenses forbid use in commercial applications.
If you are interested in the many omitted details, I recently published my notes about open source forced aligners on the forced-alignment-tools GitHub repository.
The aeneas project tries to address the issues listed above, providing an (automated) forced aligner that:
- supports many languages out-of-box,
- requires minimal installation effort,
- assumes the user has no speech processing knowledge,
- can be used in commercial products or work flows, and
- ideally, is efficient (fast).
Design Principles
Let me start by discussing the more technical issues first, to then finish with the easy bits (installation, license).
Support For Multiple Languages
The most challenging issue, among those listed above, was supporting multiple languages.
Adopting the “academic” speech recognition toolkits available at the time implied a lot of work to create training materials to produce language models. In practice that meant, for each language:
- finding a native speaker of that language;
- finding free-to-use, high-quality speech audio with accompanying text, for 2-5 hours of audio;
- making the native speaker annotate the audio;
- training an acoustic model of the language;
- finding a pronunciation lexicon (that is, a map from graphemes to phonemes) for that language.
It was clear that, even ignoring for a moment the licensing issue, I could not pursue this approach.
So, I asked around. I was just completing my PhD in Padova when I mentioned the problem to one of my friends and colleagues, who was working on a musical information retrieval problem. He suggested to look at a more classic, signal-processing-based approach, called Dynamic Time Warping (DTW). He was kind enough to pass me a proof-of-concept Python script demonstrating the technique.
ASRs systems, used as aligners, first try to recognize what the speaker says, then they align the recognized text with the ground truth text, producing the final text-to-audio synchronization map.
Instead, the DTW approach first transforms the text into synthesized audio using a text-to-speech system (TTS), then it aligns the real audio file with the synthesized audio file by minimizing a suitable distance function between an abstract matrix representation of the two audio signals, called Mel-frequency cepstral coefficients (MFCC). Combining the TTS text-to-synt-audio and the DTW synt-audio-to-real-audio maps yields the desired text-to-(real-)audio synchronization map.
Note that converting text to audio is much easier than converting audio to text, and it turns out that, for the FA purpose, the TTS does not need to sound natural, it just needs to produce intelligible audio.
Hence I modified the original script from my friend, using eSpeak as the TTS, since eSpeak is a FLOSS TTS supporting 30+ languages, hoping it was good enough for FA. After performing tests in a few languages I can understand (English, Italian, Spanish, French, German), I discovered that the MFCC+DTW approach worked extremely well for my intended application, that is, Audio-eBooks. As they say, the rest is history.
Efficiency
I kept developing aeneas in Python for a host of reasons (including that I wanted to get better at it!), but most importantly because it is a great fit for the architecture of the package I had in mind:
- lots of operations in aeneas are manipulation of configuration settings, reading and writing text files, etc. which are much easier in Python than in, say, C/C++/Java;
- I needed to call external programs
(eSpeak for the audio synthesis and
FFMpeg
for converting audio files from, say, MP3 to mono WAVE
before actually processing their information),
and Python has the extremely handy
subprocessmodule to perform those calls and collect the results; - for the actual computational core, the Python module NumPy exposes efficient implementations of signal processing and other vector algorithms;
- to tell the truth, I already knew that implementing the DTW in pure Python was not going to be particularly fast, but Python also allows to compile C code and mix it in, using the so-called Python C extensions, which eventually I implemented in the summer of 2015 and that now make aeneas pretty fast.
I promise to write more technical details in a separate post.
User Friendliness
Right now aeneas includes more than a dozen different programs in addition to the main forced aligner, but they all share the same philosophy (from Alan Kay):
Simple things should be simple, [=> default for beginners]
complex things should be possible. [=> for advanced users]
For example, think about the abstract FA task. Ideally, you want to specify just a few things:
- the path to the input audio file,
- the format and path of the input text file,
- the language of the materials, and
- the format and path of the sync map file to output.
In fact, the synopsis of the main aligner execute_task is:
$ python -m aeneas.tools.execute_task AUDIO_FILE TEXT_FILE CONFIG_STRING OUTPUT_FILE [OPTIONS]
where the CONFIG_STRING is something like:
task_language=eng|is_text_type=plain|os_task_file_format=srt
Simple and clean!
(Strictly speaking, some configuration parameters can be inferred,
for example the I/O formats can be implied by the file extensions,
or the language might be guessed from the text file contents, etc.,
but ReadBeyond business constraints suggested to make these settings explicit.
And yes, I am not entirely satisfied by the current CLI interface,
especially the CONFIG_STRING might grow very long.
I will probably change it/add a new syntax in the next version.)
On the other hand, advanced users can tweak the behavior of the tool
by passing arguments to either the CONFIG_STRING or using the
-r=RUNTIME_CONFIGURATION option.
For example, the user can modify numerical parameters of the MFCC+DTW computation,
or she can request that the transition times of the output sync map
should occur in the middle of the silence between text fragments.
Flexible and powerful!
All the CLI tools have live examples that can be run by the user on her own machine, allowing her to learn their usage:
$ python -m aeneas.tools.execute_task --example-json
[INFO] Running example task with arguments:
Audio file: aeneas/tools/res/audio.mp3
Text file: aeneas/tools/res/plain.txt
Config string: task_language=eng|is_text_type=plain|os_task_file_format=json
Sync map file: output/sonnet.json
[INFO] Creating task...
[INFO] Creating task... done
[INFO] Executing task...
[INFO] Executing task... done
[INFO] Creating output sync map file...
[INFO] Creating output sync map file... done
[INFO] Created file 'output/sonnet.json'
Finally, since I believe that extensive documentation is essential for a good FLOSS project, I put a lot of time into the help messages:
$ python -m aeneas.tools.execute_task -h
NAME
execute_task - Execute a Task.
SYNOPSIS
python -m aeneas.tools.execute_task [-h|--help|--version]
python -m aeneas.tools.execute_task --list-parameters
python -m aeneas.tools.execute_task --list-values[=PARAM]
python -m aeneas.tools.execute_task AUDIO_FILE TEXT_FILE CONFIG_STRING OUTPUT_FILE [OPTIONS]
python -m aeneas.tools.execute_task YOUTUBE_URL TEXT_FILE CONFIG_STRING OUTPUT_FILE -y [OPTIONS]
OPTIONS
--faster-rate : print fragments with rate > task_adjust_boundary_rate_value
--help : print full help and exit
--keep-audio : do not delete the audio file downloaded from YouTube (-y only)
--largest-audio : download largest audio stream (-y only)
--list-parameters : list all parameters
--list-values : list all parameters for which values can be listed
--list-values=PARAM : list all allowed values for parameter PARAM
--output-html : output HTML file for fine tuning
--rates : print rate of each fragment
--skip-validator : do not validate the given config string
--version : print the program name and version and exit
--zero : print fragments with zero duration
-h : print short help and exit
-l[=FILE], --log[=FILE] : log verbose output to tmp file or FILE if specified
-r=CONF, --runtime-configuration=CONF : apply runtime configuration CONF
-v, --verbose : verbose output
-vv, --very-verbose : verbose output, print date/time values
-y, --youtube : download audio from YouTube video
EXAMPLES
python -m aeneas.tools.execute_task --examples
python -m aeneas.tools.execute_task --examples-all
(and --help is even more detailed!) and into the
documentation,
which includes
a CLI tutorial, and
a library tutorial.
If all these are not enough,
I always keep an eye on the
aeneas mailing list.
Minimal Installation Effort
I am a power user, yet, when I started testing “academic” forced aligners, I had to waste a lot of time installing them, or, more precisely, coping with poorly documented or otherwise complex installation procedures for them. (This is a common plague for FLOSS projects, especially those coming from academia. More on this later.)
All that pain cannot be imposed to regular users. Regular users just want their problem solved. They do not care about how cool your algorithms are. They do not care about how fancy your command line argument parsing is. They want a program that takes an audio file and a text file in, and that spits a plausible file out. I knew that my tool has to be simple to install, to begin with. After all, no matter how cool (you say) your tool is, if the user cannot try it out, it will not solve her problem and she will move on to something else (or start stalking you for help).
Currently aeneas is known to run on several Linux distributions and on recent Windows and Mac OS X machines. Depending on the OS, there are several alternative paths to install it, all documented in detail.
On a typical development Linux machine which already has Python, a C compiler, etc., getting aeneas installed can be as easy as
$ sudo apt-get install espeak
$ sudo apt-get install ffmpeg
$ sudo pip install numpy
$ sudo pip install aeneas
The GitHub repository contains a Bash script to install all the dependencies, in case you have a pristine machine.
For Windows there is an
all-in-one installer,
and for Mac OS X, in addition to a similar all-in-one installer,
there will be a brew formula soon.
Additionally, if you prefer maximum dependency isolation, you can run aeneas inside a VirtualBox+Vagrant Virtual Machine that can be hosted by any OS where VirtualBox works, including Linux, Windows, and Mac OS X.
Finally, you can even use aeneas via the aeneasweb.org Web App. Register, upload your input files, specify your settings, and wait for the email with the output file in attachment. No software is required on your machine, besides a modern browser, and you can use aeneas for free. Pretty neat, eh?
Business-Friendly License
When ReadBeyond was shut down, the other partners and I agreed to publish the source code of aeneas under the GNU Affero General Public License, and they assigned its copyright back to me.
To simplify a lot, the AGPL license allows the user:
- to download the source code and run it for free on his machines;
- to modify the source code for her own needs;
- to use it for commercial purposes, including selling it or providing a service based on it.
There only two “hard” requirements of the AGPL license:
- the copyright notice and the text of the original license must be retained; and
- if modifications are distributed/sold to a third party, they must be published, effectively forcing contribution back to the public/community.
Both are pretty much compatible with any end-user application I can think of, including commercial ones. A discussion of the consequences of choosing the AGPL will appear in a subsequent blog post about the aeneas community dynamics.
Wrapping Up
In this first post of the Inside aeneas series I described the motivation behind my work on the FLOSS forced aligner aeneas and some of the design choices I made. The next posts will touch other aspects of the project, tentatively:
- a full review of the features/functions available as of v1.5.1, which I expect to stay the current stable release for a while;
- let’s talk documentation!;
- a discussion of the community that coagulated around aeneas, with a digression about funding FLOSS projects;
- a description of my vision and a tentative roadmap for the future.
As always, you can comment on this post by sending me a message.